Cost Functions
What is a Cost Function?
A cost function (also called a loss function or objective function) is a mathematical measure that quantifies how wrong a model’s predictions are compared to the actual values. It essentially tells us “how much our model costs us” in terms of prediction errors. The goal in machine learning is to minimise this cost by finding the optimal model parameters.
The Squared Error Cost Function
Looking at the following formula:
Let me break down each component:
- : The cost function value, dependent on parameters (weight) and (bias)
- : The number of training examples
- : The predicted value for the i-th example ()
- : The actual/true value for the i-th example
- : The error for a single prediction
- : Sum over all training examples
- : A normalization factor (the is often included to simplify derivatives during optimization)
Visual Interpretation
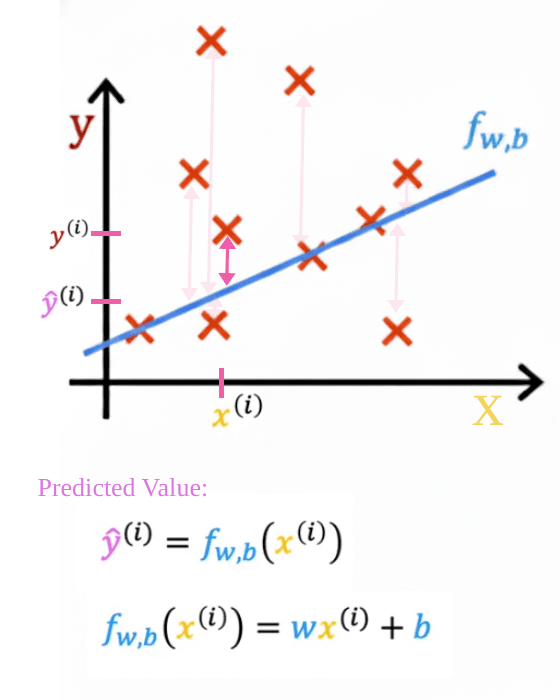 This image illustrates the squared error cost function, one of the most fundamental concepts in machine learning, particularly for regression problems.
This image illustrates the squared error cost function, one of the most fundamental concepts in machine learning, particularly for regression problems.
The graph shows:
- Red X’s: Actual data points
- Blue line: The linear model
- Pink arrows: The errors between predictions and actual values
The cost function calculates the average of the squared lengths of these pink arrows. Squaring serves two purposes:
- Makes all errors positive (so they don’t cancel out)
- Penalizes larger errors more heavily than smaller ones
The Optimization Goal
Find so that is close to for all .
The objective is to find the optimal values of and that minimize , which means finding the line that best fits the data points with the smallest overall squared error. This is typically done using optimization algorithms like Gradient Descent.
This particular cost function leads to what’s known as ordinary least squares regression when used with linear models, forming the foundation for many more complex machine learning algorithms.